HappyHorse-1.0: Why This New AI Video Model Is Getting So Much Attention
- 1. Quick Breakdown Before We Go Deeper
- 2. What Is HappyHorse-1.0, Exactly?
- 3. Why Did It Rise So Fast?
- 4. Where It Looks Strongest Right Now
- 5. The Open-Source Claim: What We Can Verify, What We Can’t
- 6. HappyHorse vs. Seedance 2.0: Where the Lead Is Real — and Where It Isn’t
- 7. What This Changes for Creators, Small Teams, and the Market
- 8. How to Evaluate HappyHorse in Real Life Instead of Just Watching the Hype
- 9. FAQ
- 10. The Bottom Line on HappyHorse-1.0
HappyHorse-1.0 matters for one reason above all: it did not enter the AI video conversation through a launch event, a product demo, or a founder thread. It entered by appearing on Artificial Analysis as a new pseudonymous video model that was already leading the no-audio text-to-video and image-to-video rankings, while placing second in the audio-enabled categories. That is not normal. It is why people are paying attention.
The harder part is this: the public story is still incomplete. The official Happy Horse site describes a 15B unified Transformer that jointly generates video and synchronized audio, supports seven lip-sync languages, and can produce 5–8 second 1080p clips. The same site also says the model, distilled checkpoint, super-resolution module, and inference code are openly released with commercial-use rights. But the GitHub repo linked from that site currently returns a 404, and the linked Hugging Face account shows 0 public models. So this is not a hands-on deployment review. It is a clearer question: what is HappyHorse-1.0, why did it rise this fast, and what can we actually verify right now?
1. Quick Breakdown Before We Go Deeper
| Signal | What looks true right now | Why it matters |
|---|---|---|
| Identity | HappyHorse-1.0 has been presented by Artificial Analysis as a pseudonymous model | The model is already influencing rankings before its ownership story is settled |
| Ranking status | It is landing #1 in no-audio text-to-video and image-to-video, and #2 in the audio-enabled categories | This is a strong preference signal, not just a spec-sheet claim |
| Official positioning | The official site frames it as a 15B unified Transformer for joint video + audio generation | The pitch is much bigger than “another text-to-video model” |
| Public verifiability | The site claims open release and commercial use rights, but the linked GitHub repo 404s and Hugging Face has no public model yet | This is the biggest trust gap in the story |
| Best current read | Strong signal, incomplete proof | Worth serious attention, but not blind certainty |
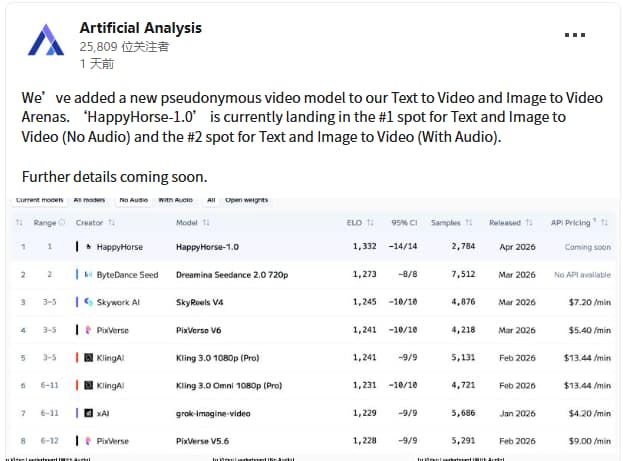
One source is carrying most of the “this is real” weight right now: Artificial Analysis described HappyHorse-1.0 as a new pseudonymous model and said it was taking the top spot in no-audio text-to-video and image-to-video, while placing second in the audio-enabled categories. The official site is carrying most of the “this is what the model claims to be” weight. Those are not the same thing. Keep them separate and the story gets much easier to read.
Bottom line: HappyHorse-1.0 already has the kind of ranking signal that forces attention, but it does not yet have the kind of public release trail that earns automatic trust.
2. What Is HappyHorse-1.0, Exactly?
The short answer is that HappyHorse-1.0 is being framed as a unified multimodal video system, not just a silent video generator with audio bolted on later. The official site says it is a 15B-parameter Transformer that jointly produces video and synchronized audio from text or image prompts, supports seven lip-sync languages, uses a 40-layer self-attention architecture, and aims at 5–8 second 1080p clips. That is the product definition being presented to the public.
You can also get a clearer sense of how Happy Horse 1.0 is being positioned from current example clips like the one below, which leans into the kind of short, polished, performance-led output now shaping the conversation around the model.
That description matters because it changes what people think they are looking at. If the pitch were simply “a better diffusion video model,” this would be a rankings story. Instead, the pitch is closer to: one model, one pass, one output stream where dialogue, ambient sound, and lip sync are solved together. That is a much more ambitious claim. It also explains why the discussion moved so quickly from “nice leaderboard result” to “does this change the balance between open and closed systems?”
I would not write this as a conventional “tested review” yet. The public information is enough to explain what HappyHorse says it is. It is not enough to treat every deployment claim as settled. That distinction is the difference between a useful article and a hype post.
Bottom line: HappyHorse-1.0 should be understood first as a claimed unified audio-video generation system, and only second as a new leaderboard entry.
3. Why Did It Rise So Fast?
The answer is not “because people love parameters.” Artificial Analysis is useful here precisely because its ranking is based on blind user preference, not on a lab-style architecture scorecard. 36Kr’s coverage made the same point: the ranking is built from real-user blind tests, which makes the reaction harder to dismiss as a marketing trick or a benchmark loophole.
My read is that HappyHorse is benefiting from something more human than a technical novelty. When people vote on short clips, they are not evaluating model cards. They are reacting to whether a result feels watchable, coherent, and finished. If a model makes 5–8 second clips feel less like stitched motion and more like a single directed beat, that tends to win attention fast. The official positioning around joint audio-video generation points in exactly that direction, even if the broader public proof is still catching up.
This is also why the story spread so quickly. Anonymous models do not usually get the benefit of the doubt. They get suspicion. HappyHorse got suspicion too. But it got attention anyway, because the ranking result arrived first. People had to explain a signal that was already in front of them.
Bottom line: HappyHorse rose quickly because the ranking signal hit before the backstory did, and blind-preference wins are hard to wave away.
4. Where It Looks Strongest Right Now
The weakest way to write about HappyHorse is to call it “the best video model, period.” That tells the reader nothing. The better question is where it appears most likely to establish an edge first. Based on the official positioning and the way the story is being discussed, the most plausible answer is not “everything.” It is people-centered short video: portrait shots, talking-head formats, image-led clips, digital human content, and short scenes where synchronized speech and facial timing matter more than spectacular physics.
That does not mean it cannot perform elsewhere. It means the strongest current case is narrower. The official site itself leans into synchronized dialogue, ambient sound, Foley, multilingual lip sync, and social-ready 1080p clips. 36Kr also framed the opportunity in vertical terms, pointing to portraits, digital humans, and virtual anchors as the sort of use cases where an open model reaching a “deliverable” threshold would actually change the cost structure.
The clip below fits that narrower read quite well: short-form, performance-led, and built around watchability rather than spectacle alone.
That is a more useful way to think about it. Not as a magic universal winner. As a model that may have found a very commercially relevant wedge.
Bottom line: The strongest current read is not “HappyHorse solves video.” It is “HappyHorse may be especially meaningful where faces, voices, and short-form delivery matter most.”
5. The Open-Source Claim: What We Can Verify, What We Can’t
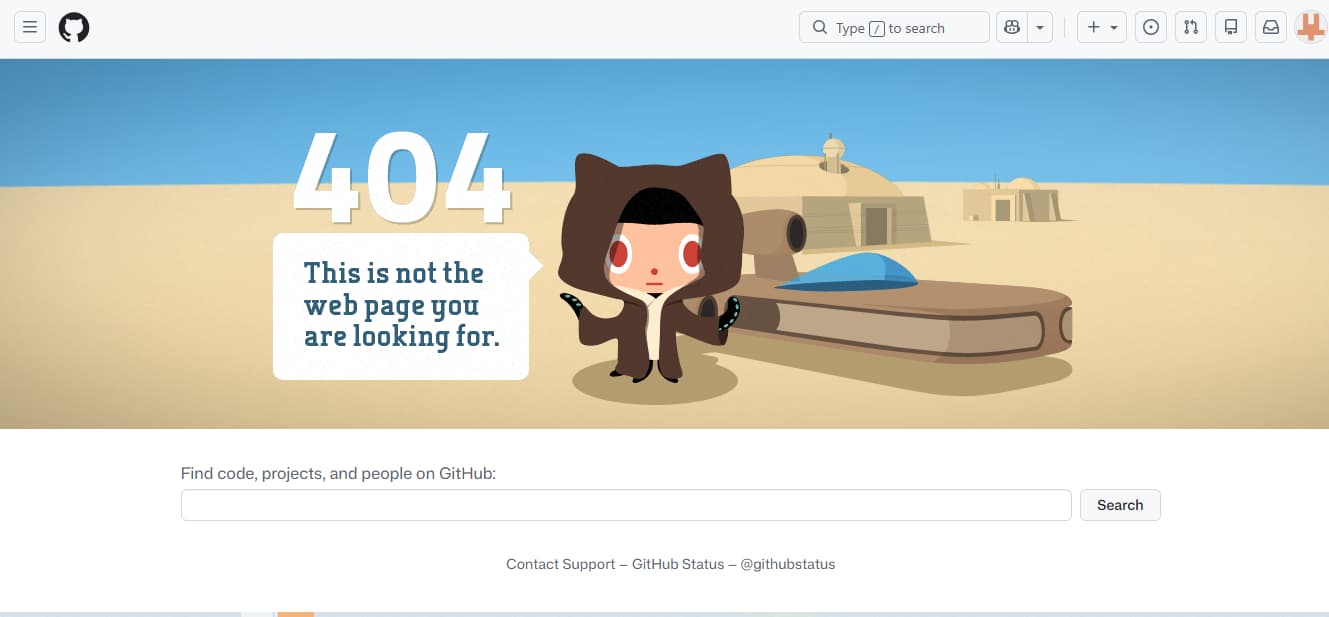
This is the part that most articles still blur.
What can be verified is simple. The official Happy Horse site says the project is open source, includes commercial-use rights, and releases the base model, distilled model, super-resolution module, and inference code. It even provides sample commands for cloning a GitHub repo and loading a pretrained model from Hugging Face. Those claims are plainly on the site.
What cannot be waved through is whether those public release claims are already matched by accessible, verifiable artifacts. The GitHub repo linked from the site currently returns 404 Not Found. The linked Hugging Face account shows models 0 and “None public yet.” That does not prove the release will not happen. It does mean that “fully open-source and publicly verifiable today” is too strong a sentence right now.
That gap matters more than people think. In AI video, “open” can mean at least three different things:
- a public claim on a marketing page
- a downloadable artifact with terms
- a reproducible release that third parties can actually run
HappyHorse may still get to the third bucket. Today, the public evidence is much closer to the first than the third. That is why the right editorial tone is not disbelief. It is restraint.
Bottom line: HappyHorse’s open-source story is a serious claim, but public verifiability has not yet caught up with the language being used around it.
6. HappyHorse vs. Seedance 2.0: Where the Lead Is Real — and Where It Isn’t
The cleanest thing to say is this: if your standard is blind user preference in the no-audio categories, HappyHorse has already made the strongest possible entrance. That part is real enough to matter. 36Kr explicitly framed the moment as HappyHorse overtaking Seedance 2.0 on Artificial Analysis and turning the rankings into a genuine signal rather than another speculative launch narrative.
The part that should be written more carefully is everything after that. “Beating Seedance” can mean a few very different things. It can mean users preferred a set of clips in a blind arena. It can mean the model is easier to access. It can mean the model is more reproducible. It can mean the model is a better business choice today. Those are not interchangeable. And right now, HappyHorse only has a clear lead in the first sense.
That is still a big deal. But it is not the same as saying the market has flipped. Even the more bullish 36Kr framing stops short of that and says HappyHorse will not shake Seedance or Kling in the short term. That feels like the right level of caution. This looks more like a warning shot than a total regime change.
Bottom line: HappyHorse has earned the right to be compared with Seedance seriously, but it has not earned the right to be written as the settled winner of every category that matters.
7. What This Changes for Creators, Small Teams, and the Market
The real story here is pricing power.
For a long time, closed-source video products could rely on a simple argument: open models were interesting, but not good enough to ship client-facing work. 36Kr says that gap is exactly where closed players built much of their pricing power, and that is why this moment matters. If an open or quasi-open model can get close enough to “deliverable” quality in human-rated blind tests, the market starts asking a different question: what exactly are we paying the premium for now?
That does not instantly rewrite the stack. Teams still care about availability, support, uptime, moderation, documentation, and predictable output. Closed products still win on a lot of those. But this is where the story gets interesting. 36Kr framed the appearance of HappyHorse as a real open-vs.-closed pricing-power signal, especially in portrait, digital-human, and virtual-anchor scenarios where self-hosting economics could change fast once quality crosses the threshold from “usable” to “deliverable.”
That is the deeper reason not to dismiss this as a curiosity. Even if HappyHorse itself remains partly unresolved for a while, the market signal is already out.
Bottom line: HappyHorse matters because it pressures the story that closed models are the only credible route to shippable video quality.
8. How to Evaluate HappyHorse in Real Life Instead of Just Watching the Hype
If you actually want to judge what this moment means, do not start with abstract arguments about who built it. Start with tasks.
Use one portrait. Use one talking-head script. Use one product image. Use one short scene description. Then compare outputs on the things that matter when a clip needs to leave the testing folder:
- Shot coherence — does the clip feel like one beat or a sequence of disconnected guesses?
- Face stability — do identity and expression hold up from start to finish?
- Audio-picture fit — if speech is involved, does the clip look solved or stitched?
- Re-run reliability — if you need three usable versions, do you get three, or one lucky outlier?
That is why I would not wait for every rumor around HappyHorse to be resolved before building your own baseline. If HappyHorse eventually becomes fully public and reproducible, that baseline will become even more valuable. If it does not, you still learned something useful: what kind of clip quality your workflow actually needs.
Upload one reference image and run your own side-by-side test
Bottom line: The right response to the HappyHorse hype cycle is not belief or disbelief. It is controlled comparison.
9. FAQ
What is HappyHorse-1.0?
HappyHorse-1.0 is a pseudonymous AI video model that Artificial Analysis says is landing #1 in no-audio text-to-video and image-to-video, and #2 in the audio-enabled categories. The official site describes it as a 15B unified Transformer that jointly generates video and synchronized audio from text or image prompts.
Is HappyHorse-1.0 open source?
It is being presented that way on the official site, which says the model, distilled checkpoint, super-resolution module, and inference code are openly released with commercial-use rights. But the linked GitHub repo currently returns 404, and the linked Hugging Face account has no public model yet. So the safest wording today is: claimed open source, not yet fully publicly verifiable.
Is HappyHorse better than Seedance 2.0?
It depends on what “better” means. The strongest public case today is that HappyHorse is already winning attention in blind user-preference arenas. That is not the same as proving it is easier to access, easier to reproduce, or the better production choice for every team right now.
Can you use HappyHorse-1.0 today?
You can study the public claims today. You can talk about the ranking signal today. What is still unclear is whether a third party can independently access and reproduce the full release as described on the official site without hitting missing links or missing artifacts.
Who should pay the most attention to HappyHorse right now?
Teams working on portraits, digital humans, virtual presenters, talking-head video, and short-form image-led clips should watch it closely. That is where the current combination of ranking signal and official feature claims looks most commercially relevant.
10. The Bottom Line on HappyHorse-1.0
HappyHorse-1.0 is not interesting because it arrived with a polished product story. It is interesting because it arrived without one and still forced its way into the center of the AI video conversation. Artificial Analysis has already given it a ranking signal that people cannot ignore. The official site has given it an ambitious identity. The public release trail has not caught up yet. That tension is the story.
My judgment is simple. Treat HappyHorse as a serious market signal, not as a fully settled fact pattern. If your work depends on short, people-centered video, this is one of the few new models worth following closely. If you need a fully transparent, fully documented, fully reproducible release today, the public evidence is not there yet.
And that is enough. More than enough, actually. Because once a model can win user preference before it wins perfect clarity, every closed video lab has to start taking the threat seriously.