I Tested Seedance 2.0: Multimodal Video, Reference Control & Editing

- What Changed: Seedance 2.0 Now Thinks in Four Modalities
- The Biggest Highlight: Reference Ability (This Is the Real 2.0)
- What It Feels Like in Practice: The “@ Reference” Workflow
- The Quiet Upgrade That Matters: Base Quality Got Better
- Real-World Limits You Should Know (Before You Get Confused)
- Why This Matters: Seedance 2.0 Is “Controllable Creativity”
- My Closing Thought
I still remember the era when “making an AI video” meant one thing: type a prompt, maybe add a first frame and a last frame, and hope the model somehow tells the story you had in mind.
That workflow always felt like whispering instructions through a wall.
So when I heard Seedance 2.0 was built around a different idea — not just generating video, but understanding references — I had to try it. After testing it, my takeaway is simple:
Seedance 2.0 isn’t only a multimodal upgrade. It’s a control upgrade.
It’s the first time I’ve felt like I’m not begging the model for a result… I’m actually directing.
What Changed: Seedance 2.0 Now Thinks in Four Modalities
Seedance 2.0 supports four kinds of input:
- Images (up to 9)
- Videos (up to 3, total ≤ 15s)
- Audio (MP3, up to 3, total ≤ 15s)
- Text (natural language)
And here’s the key: you’re not forced into one “correct” input style.
I can use one image to lock the style, use a video to define motion + camera language, and then use a few seconds of audio to set rhythm and mood — all while using plain English (or any natural language) to explain what I want.
That “Free combination” feeling is real: I’m not writing prompts anymore; I’m assembling a creative stack.
The Biggest Highlight: Reference Ability (This Is the Real 2.0)
If I had to summarize Seedance 2.0 in one sentence:
It’s a model that can “reference the world” and stay loyal to what you give it.
The reference upgrades show up in four ways:
1) Reference Images That Actually Respect Composition and Details
I tested with style-and-character-heavy images, and the best improvement was this: composition holds, character details persist, and it doesn’t “drift” as quickly into generic faces or vague props.
2) Reference Videos That Understand Camera Language + Complex Motion
This is where it feels like a different product.
Instead of describing “push-in, whip pan, follow shot, fast rhythm, transition effect…” in a wall of text, I can just say:
- “Reference the camera movement and cut rhythm from @video1”
- “Copy the action tempo and creative effects from @video2”
And it actually does it — including complex action timing, creative transitions, and stylized effects.
3) Smooth Video Extension: Not Just Generate — “Keep Filming”
Seedance 2.0 supports extending an existing video and connecting clips more smoothly.
That matters because real creation isn’t always “start from zero.” Sometimes I just want: “Continue this shot for 5 seconds, keep the motion and mood consistent.”
Seedance 2.0 finally treats that as a first-class workflow.
4) Editing Is Stronger: Replace / Remove / Add Inside an Existing Video
This is a subtle but huge shift: video creation isn’t only generation anymore.
Seedance 2.0 can take an existing video and let me specify:
- replace a character
- delete or reduce a part
- add an element
- redirect the story beat
It’s the difference between “output” and “control.”
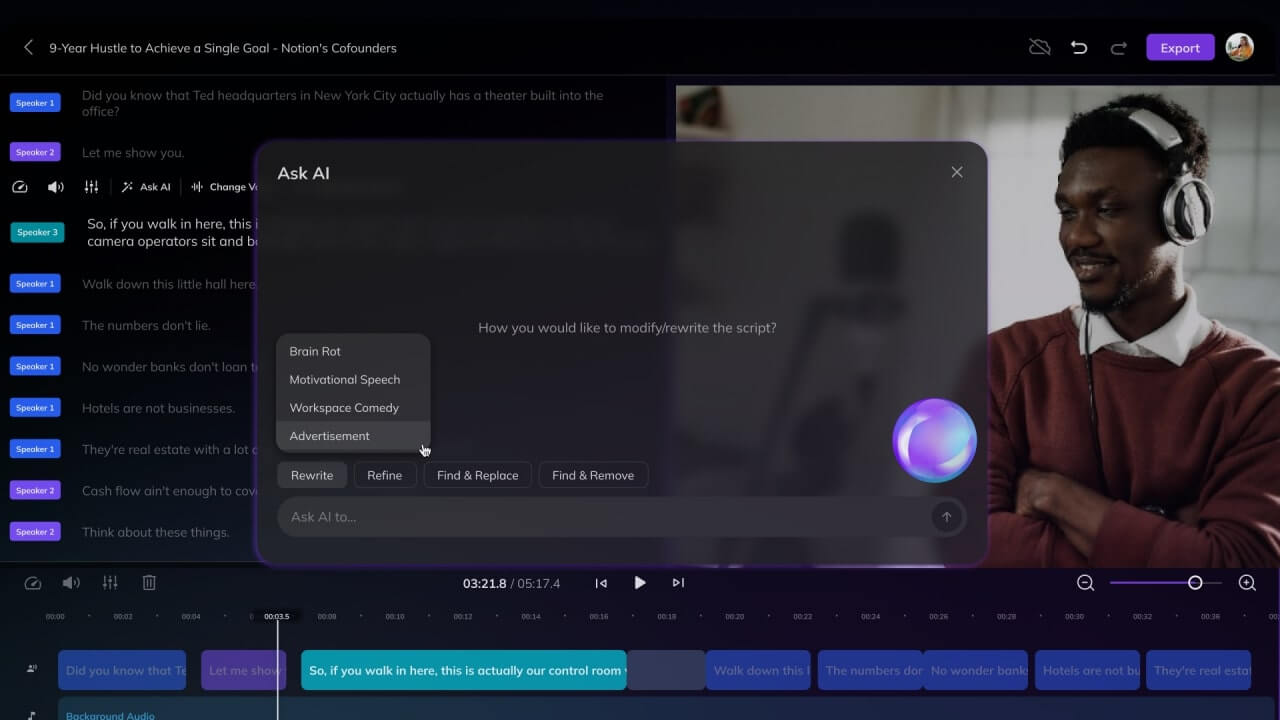
What It Feels Like in Practice: The “@ Reference” Workflow
The interaction design is surprisingly practical.
There are two main entry points:
- First/Last Frame mode (good if it’s just a first-frame image + prompt)
- All-Purpose Reference mode (needed for mixed multimodal inputs)
Inside All-Purpose Reference, everything is driven by a simple idea:
You assign roles by typing @filename
Example thinking pattern:
@image1as the first frame (style lock)@video1to reference camera language + motion rhythm@audio1for background music / timing- then write the prompt like you’re briefing an editor + cinematographer
It’s not complicated — but it changes the way you prompt. You stop describing everything abstractly, and you start pointing at concrete references.
The Quiet Upgrade That Matters: Base Quality Got Better
Multimodal is the headline, but Seedance 2.0 also feels improved in fundamentals:
- motion looks more natural
- physical behavior feels more reasonable
- instruction-following is more precise
- style consistency is more stable
- the result looks smoother and more “real”
If 1.0 felt like “sometimes magic, sometimes chaos,” 2.0 feels like “still creative, but far more dependable.”
Real-World Limits You Should Know (Before You Get Confused)
A few practical constraints I had to adapt to:
- Total mixed input limit: 12 files (images + videos + audio combined)
- Output length ≤ 15s (you can choose 4–15s)
- Video references can be more expensive than other inputs (worth planning for)
- Realistic human faces are currently restricted for upload (images/videos containing clear real human faces may be blocked due to compliance)
That last one is important: if you try to upload a real person’s face and it fails, it’s not your workflow — it’s a platform constraint.
Why This Matters: Seedance 2.0 Is “Controllable Creativity”
A lot of video models are judged by a single question:
“Can it generate a cool clip?”
But real creators care about a different question:
“Can it generate the clip I’m trying to express?”
Seedance 2.0 moves toward that second question.
Because the upgrade isn’t just “more modalities.” It’s that the model now treats reference as a core primitive — and reference is how directors, editors, and designers actually work.
My Closing Thought
When I tested Seedance 2.0, I didn’t feel like I was gambling on a prompt.
I felt like I was building a scene:
- lock style with an image
- define motion and camera with video
- set mood and timing with audio
- then use text to tell it what matters
That workflow is closer to real filmmaking than anything I’ve tried in this category.
Seedance 2.0 is where multimodal video creation stops being “just generation” and starts becoming “directable.”
Seedance 2.0 — bold ideas first. Let the model handle the rest.